/edge_tts
├── exec_script_py.php ← Script PHP que crida Python des de la web
├── generar_tts.py ← Genera l'àudio amb Edge TTS
├── generar_gtts.py ← Versió que utilitza Google TTS
├── generar_veu.py ← Alternativa o prova per generar veu
├── diagnostic_edge_tts.py ← Diagnòstic o comprovació del servei TTS
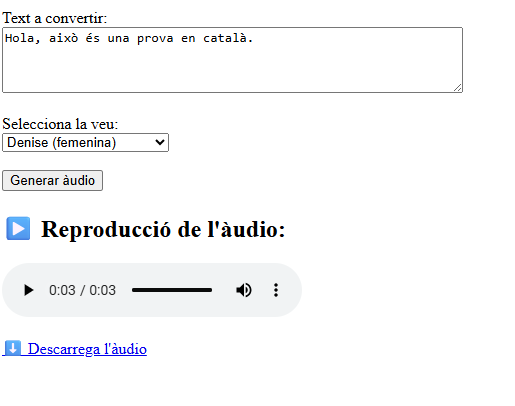
├── index.php ← Interfície web principal del projecte
├── tts.mp3 ← Fitxer d’àudio generat (resultat final)
├──
├── env_tts/ ← Entorn virtual Python dedicat a TTS
├── venv/ ← Possible entorn virtual duplicat
├── venv_web/ ← Potser creat per a la web; revisa si s’usa
└── edge_tts/ ← Pot contenir recursos o mòduls complementaris
Entorn
la carpeta té crear un entorn virtual amb una versió específica de Python especifica:
index.php
<?php
// Llista de veus
$voices = [
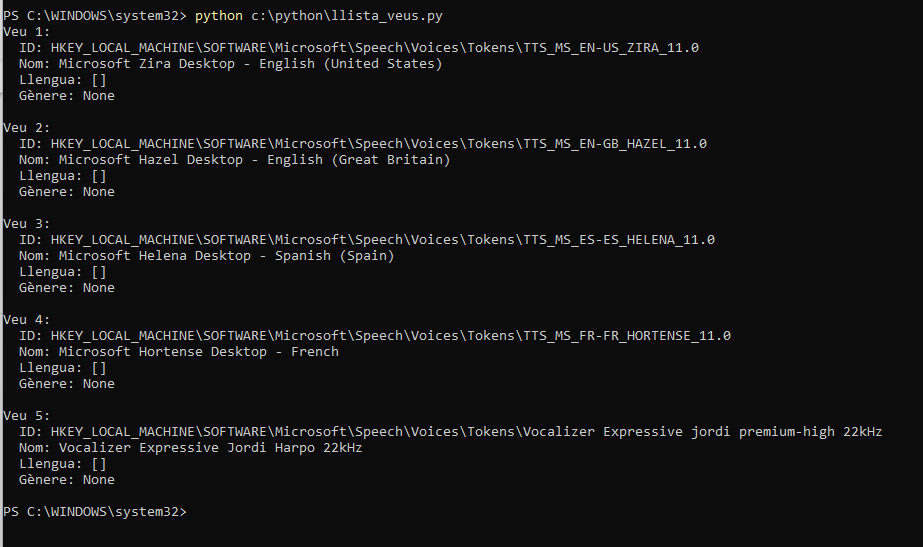
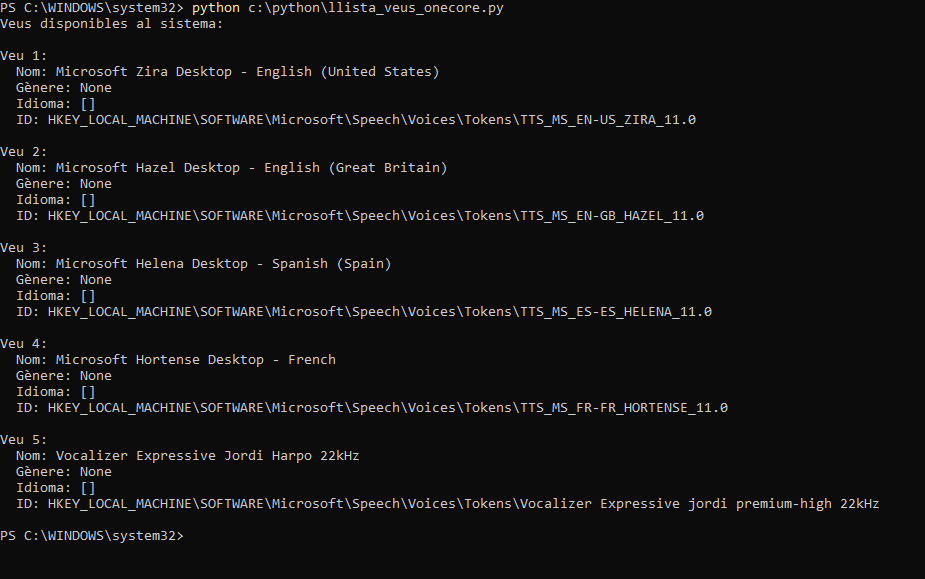
"Microsoft Helena Desktop",
"Microsoft Hazel Desktop",
"Microsoft Zira Desktop",
"Microsoft Hortense Desktop",
"Vocalizer Expressive Jordi Harpo 22kHz"
];
// Carrega valors antics per mantenir-los al formulari
$lastText = isset($_GET['text']) ? htmlspecialchars($_GET['text']) : '';
$lastVoice = isset($_GET['voice']) ? $_GET['voice'] : '';
?>
<!DOCTYPE html>
<html lang="ca">
<head>
<meta charset="UTF-8">
<title>Generador TTS</title>
</head>
<body>
<h1>Text-to-Speech (amb Python)</h1>
<form action="exec_script_py.php" method="post">
<label for="text">Introdueix el text:</label><br>
<textarea name="text" id="text" rows="4" cols="50"><?= $lastText ?></textarea><br><br>
<label for="voice">Selecciona una veu:</label><br>
<select name="voice" id="voice">
<?php foreach ($voices as $voice): ?>
<option value="<?= htmlspecialchars($voice) ?>" <?= ($voice == $lastVoice ? 'selected' : '') ?>>
<?= htmlspecialchars($voice) ?>
</option>
<?php endforeach; ?>
</select><br><br>
<input type="submit" value="Generar àudio">
</form>
<?php if (isset($_GET['error'])): ?>
<p style="color:red;">❌ Error: <?= htmlspecialchars($_GET['error']) ?></p>
<?php endif; ?>
<?php if (file_exists("tts.mp3")): ?>
<h2>Resultat:</h2>
<audio controls>
<source src="tts.mp3?<?= time() ?>" type="audio/mpeg">
El teu navegador no suporta àudio.
</audio>
<?php endif; ?>
</body>
</html>
generar_tts.py
import sys
import os
from gtts import gTTS
# Agafa el directori actual del fitxer Python
base_dir = os.path.dirname(os.path.abspath(__file__))
output_path = os.path.join(base_dir, "tts.mp3")
# Recollir text i veu
text = sys.argv[1] if len(sys.argv) > 1 else "Text per defecte"
voice = sys.argv[2] if len(sys.argv) > 2 else "default"
print(f"▶ Text: {text}")
print(f"▶ Veu seleccionada: {voice} (no utilitzada per gTTS)")
print(f"▶ Fitxer a guardar: {output_path}")
# Generar MP3
tts = gTTS(text=text, lang='ca')
tts.save(output_path)
exec_script_py.php
<?php
if ($_SERVER['REQUEST_METHOD'] === 'POST') {
$textRaw = $_POST['text'] ?? '';
$voiceRaw = $_POST['voice'] ?? '';
// Guarda per reenviar després
$text = escapeshellarg($textRaw);
$voice = escapeshellarg($voiceRaw);
// DEBUG: mostra quin python s'està usant
$pythonPath = shell_exec("where python3");
echo "<pre>Python detectat:\n$pythonPath</pre>";
// Crida python del synology? o pytho windows 11 amb la comanda real
$command = "/bin/python3 generar_tts.py $text $voice 2>&1";
$output = shell_exec($command);
echo "<pre>Sortida execució:\n$command\n\n$output</pre>"; // Ajuda per depuració
// Comprova si s'ha creat l'àudio
if (!file_exists("tts.mp3")) {
$error = "No s'ha pogut generar l'àudio. Sortida: $output";
header("Location: index.php?error=" . urlencode($error) . "&text=" . urlencode($textRaw) . "&voice=" . urlencode($voiceRaw));
exit();
}
// Redirigeix a index amb el text i veu conservats
header("Location: index.php?text=" . urlencode($textRaw) . "&voice=" . urlencode($voiceRaw));
exit();
}
?>